What is HIVE ??

Apache Hive is an open-source data warehouse system for querying and analyzing large datasets stored in Hadoop files. Hadoop is a framework for handling large datasets in adistributed computing environment.
Getting Started
We will be using the same data that we used in our hive tutorial. Namely, files batting.csv and master.csv.
Data Source
Accessing Hue
You can access HUE from the entering the address 127.0.0.1:8000
Login Id : Hue
Pwd : 1111
Uploading Data
Data is uploaded into the directory user/hue from the HDFS file system. The steps to upload the files into this directory are available on my previous blogs.
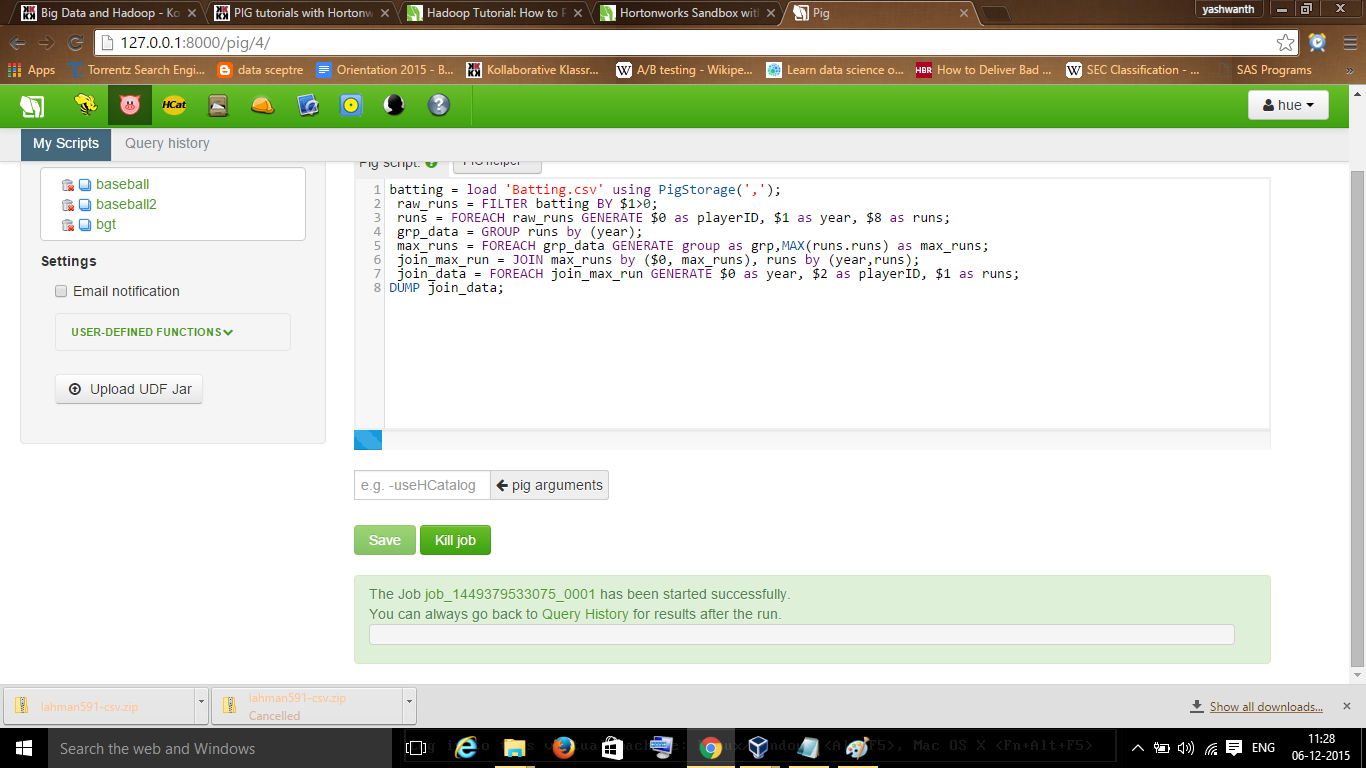
Writing Queries
You click on the query editor to go to the query page.
Queries
The 1st step we do is create a temp_batting table with the query.

You can see tables by clicking 'Table' option.

Loading CSV file


Creating table


Which player has scored how much for given runs ?

Thank you.
create table temp_batting (col_value STRING);You can see tables by clicking 'Table' option.
Loading CSV file
LOAD DATA INPATH '/user/hue/Batting.csv' OVERWRITE INTO TABLE temp_batting;SELECT * FROM temp_batting LIMIT 100;
Creating table
create table batting (player_id STRING, year INT, runs INT);
Now we extract the data we want from temp_batting and copy it into batting. We do it with a regexp pattern and build a multi line query.
The 1st line will overwrite the blank data into the batting table. Next 3 lines will extract player_id, year and runs fields form the temp_batting table.
insert overwrite table batting SELECT regexp_extract(col_value, '^(?:([^,]*)\,?){1}', 1)player_id, regexp_extract(col_value, '^(?:([^,]*)\,?){2}', 1) year, regexp_extract(col_value, '^(?:([^,]*)\,?){9}', 1) run from temp_batting;Once the query is executed we can see the job status by entering the below address in your web browser 127.0.0.1:8088 and you can get a status as below.
Grouping Data
Which player has scored how much for given runs ?
SELECT a.year, a.player_id, a.runs from batting a JOIN(SELECT year, max(runs) runs FROM batting GROUP BY year )b ON (a.year = b.year AND a.runs = b.runs) ;Thank you.