Introduction









Apache Pig is a platform for analyzing large data sets. Pig's language, Pig Latin, is a simple query algebra that lets you express data transformations such as merging data sets, filtering them, and applying functions to records or groups of records. Users can create their own functions to do special-purpose processing.
Pig Latin queries execute in a distributed fashion on a cluster. Our current implementation compiles Pig Latin programs into Map-Reduce jobs, and executes them using Hadoop cluster.
Problem statement
We are going to read in a baseball statistics file. We are going to compute the highest runs by a player for each year. This file has all the statistics from 1871–2011 and it contains over 90,000 rows. Once we have the highest runs we will extend the script to translate a player id field into the first and last names of the players.
Link for datasets: http://hortonassets.s3.amazonaws.com/pig/lahman591-csv.zip
We start virtual box to get hadoop started, then we will see a GUI screen like below.

Upload .csv files using upload button on right corner.

Now we can go to Pig console by clicking pig image on title bar which leads us to pig console where we can write, edit and save pig commands.

Steps:
1. We need to load the data first. For that we use load statement.
2. To filter out the first row of the data we add FILTER statement.
3. Now we name the fields, We will use FOREACH statement to iterate batting data object. We can use Pig helper to provide us with a template if required.So the FOREACH statement will iterate through the batting data object and GENERATE pulls out selected fields and assigns them names. The new data object we are creating is then named runs.
4. We will use GROUP statement to group the elements in runs by the year field.
5. We will use FOREACH statement to find the maximum runs for each year.
6. We use the maximum runs we need to join this with the runs data object so we can pick up the player.
7. The result will be a dataset with "Year, PlayerID and Max Run".
8. At the end we DUMP data to the output.
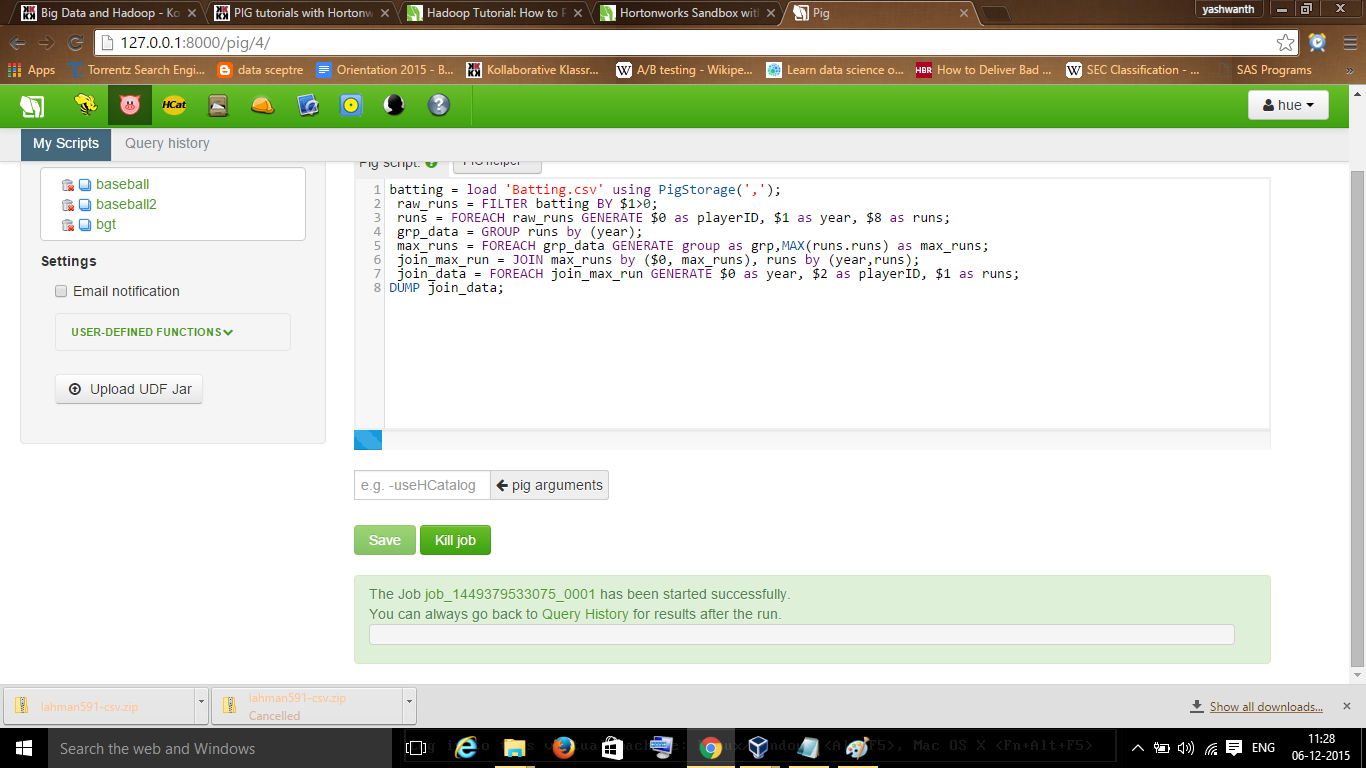
Save and execute-

We can see job status-

Results and logs in query history-

We can see the results as we mentioned in the code as "Year", "Player_id", and "Max_run".

We should always check the log to see if the script was executed correctly.

seen
ReplyDelete